
Proportionality: Not Every AI Decision Needs a Committee
A nonprofit operations director sent me a 14-page proposal in March. Subject line: "AI Ethics Committee approval required for typo autocorrect."
The proposal was real. The committee was real. The committee had been formed six months earlier with a 12-person roster including the executive director, two board members, the IT director, the development director, and outside counsel. The committee met monthly. Every AI use case in the organization went through the same review.
The autocorrect proposal had been in the queue for four weeks. The proposed change: enable Salesforce's standard autocorrect on the Donor Name field, which would suggest "Christopher" when someone typed "Christoper." A reviewer would still confirm before saving.
Four weeks. Twelve people. Outside counsel. For autocorrect.
The same committee had approved an Agentforce deployment two weeks earlier in 30 minutes. The Agentforce deployment had authority to draft and send donor communications.
Both went through the same review. One was overgoverned. One was undergoverned.
This is what the fifth guiding principle of the CCC AI Center of Excellence addresses.
The Principle
Proportionality. Governance controls are proportional to risk. Low-risk automations receive lighter review. High-impact AI decisions receive mandatory multi-step validation.
That sentence is not a permission slip to skip governance. It is a permission slip to focus governance where it matters.
The opposite of proportionality is governance theater. Governance theater treats every decision the same. The committee meets. The forms get filled out. The board hears reports. Risk is not actually managed since the committee is too busy reviewing autocorrect to study the agent that can send communications to 18,000 donors.
Proportional governance reverses that. Light controls for low-risk. Heavy controls for high-risk. Explicit, written, applied consistently.
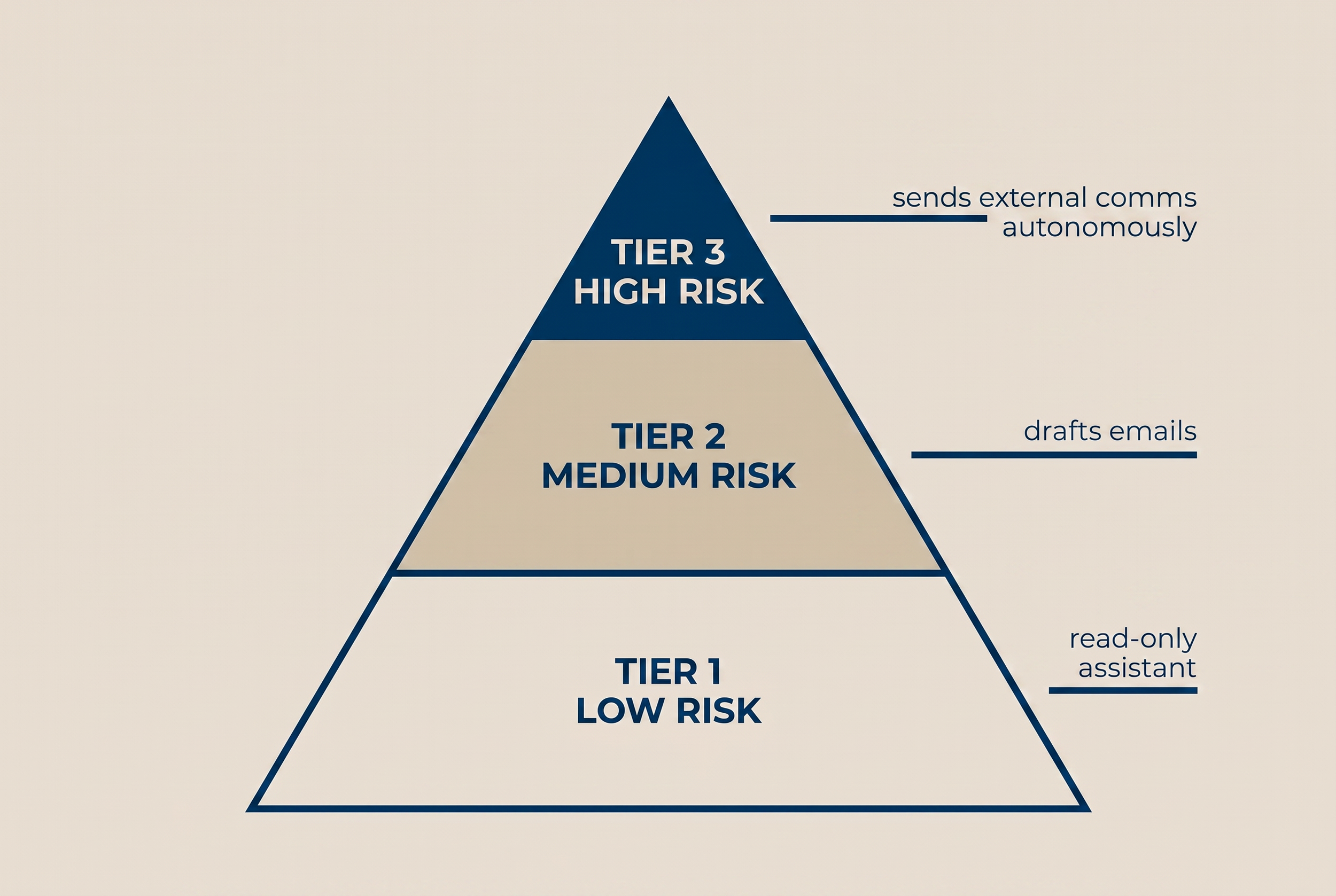
The Risk Classification System
Every AI use case in a CCC engagement gets classified into one of three tiers before any governance review happens. The classification takes about 15 minutes. It runs through five questions: data sensitivity, action authority, reversibility window, external communication scope, and regulatory exposure.
Tier 1: Low-risk
Characteristics: read-only, reversible within seconds, no external communication, no record modification, no financial impact, no regulatory exposure.
Examples: an autocorrect suggestion that requires user confirmation. An AI-generated meeting summary in a Slack channel that anyone can edit. A search-relevance ranking on internal documentation. A quick-text suggestion in an email composer that the user reviews before sending.
Governance controls: documentation in the AI inventory, named owner, vendor security review, end-user notification. No committee. No multi-step approval. The system administrator can enable it.
Review timeline: typically one week. Sometimes one day if the inventory and AUP are mature.
Tier 2: Medium-risk
Characteristics: writes to the system but operates within a constrained scope, modifies non-sensitive records, communicates internally only, reversible within minutes to hours, no PHI or PII exposure beyond what users already access.
Examples: an Einstein NBA recommendation surfacing on Lead pages. An Agentforce assistant that drafts case responses for human review before sending. A predictive lead score that influences routing but does not commit any record action. A summarization tool that writes activity records back to Account history.
Governance controls: everything from Tier 1, plus written human-review gate documentation, scope-boundary statement, kill-switch procedure, training plan for affected users, 30-day post-launch review.
Review timeline: two to four weeks. Includes one round of pilot testing with at least three users.
Tier 3: High-risk
Characteristics: agentic action authority, modifies sensitive records, sends external communication, processes PHI or PII at scale, irreversible without manual remediation, has financial or regulatory consequences if wrong.
Examples: an Agentforce agent with authority to draft and send donor outreach. An AI-driven case escalation that pages on-call clinicians. An automated grant matching tool that surfaces eligibility recommendations to applicants. A patient triage assistant that classifies symptom severity. A federal-agency AI system subject to OMB M-25-21 reporting.
Governance controls: everything from Tier 2, plus risk classification documentation, executive sponsor sign-off, multi-stage human review (design, pre-launch, post-launch), bias and fairness testing, rollback drill, incident response runbook, board-level reporting cadence, external compliance review when applicable.
Review timeline: six to twelve weeks. Includes documented bias testing, a tabletop incident exercise, and at least two rounds of pilot testing.
What Proportionality Actually Catches
The reason proportional governance works is that it forces classification before review. The forcing function is the classification questions, not the review tier.
Three patterns surface during classification that would not show up in a one-size-fits-all review.
The "wait, this is Tier 3" surprise. Teams routinely classify their proposed deployments at lower tiers than the use case actually warrants. The autocorrect was Tier 1. Easy. The Agentforce deployment got pitched as Tier 2 because the team was thinking about the technical scope, not the action authority. When we ran the classification questions ("Does this deployment send communications to external parties?" "Is the action authority reversible without manual intervention?"), the deployment moved to Tier 3. The committee approval that originally took 30 minutes had to be redone over four weeks with the appropriate controls.
The "this is actually Tier 1" relief. Equally common. A proposed AI feature gets routed to a heavyweight review because the org has only one review process. The classification reveals the actual risk is Tier 1. Review collapses from four weeks to one. Real example: a fundraising team wanted to enable Einstein-suggested email subject lines. The committee was treating it as Tier 3 because "AI" and "external communication" appeared in the description. The actual deployment: the user sees a suggestion, edits or rejects it, then clicks send. Reviewable, reversible, user-confirmed every time. Tier 1. Approved in three days.
The hidden Tier 3. The most important pattern. Tier 3 deployments often arrive disguised as smaller projects. A "simple" Flow that calls an AI service for record matching looks like an automation update. Once you ask whether the action authority is reversible (no, the merge is irreversible), whether external communication is involved (the post-merge confirmation email goes to the contact), and whether regulatory exposure exists (yes, if the org handles PHI or PII), the deployment moves to Tier 3. The Flow update becomes a multi-week governance review. That is the right outcome. The wrong outcome is letting the Flow ship as a routine config change.
How to Run a Classification
The five questions, in the order I run them in CCC engagements:
Does this AI deployment have action authority that modifies records, sends communication, or commits transactions? If yes, minimum Tier 2.
Is the action reversible without manual remediation within minutes? If no, increase one tier.
Does the system handle PHI, PII at scale, financial data, or regulated content? If yes, increase one tier.
Does the deployment communicate externally to clients, donors, patients, or the public? If yes, minimum Tier 2 even if everything else is low.
Is there a named human owner who personally reviews each AI-assisted decision before action? If no, increase one tier.
Five questions. About 15 minutes. The questions are deliberately structured so that any single high-risk attribute pushes the classification up. This is intentional. False negatives in classification produce real incidents. False positives produce annoyance. Annoyance is recoverable.
Where Proportionality Fits in the Charter
Articles 1 through 4 in this series covered Data First, Human Oversight, Transparency, and Accountability. Each of those principles applies at every tier. What changes by tier is the depth of application.
Data First at Tier 1: spot-check the data quality of the relevant fields. Data First at Tier 2: run the 10-metric SOQL audit on the affected objects. Data First at Tier 3: full data quality review, sharing model audit, integration user review.
Human Oversight at Tier 1: the user confirms before action. Human Oversight at Tier 2: a documented review gate before any external action, named owner. Human Oversight at Tier 3: multi-stage review with executive sponsor, kill switch tested, escalation path documented.
Transparency at Tier 1: end-user notification that AI is being used. Transparency at Tier 2: four-audience documentation per the Article 4 standard. Transparency at Tier 3: four-audience documentation plus board-level reporting plus compliance attestation.
Accountability at Tier 1: named owner in the inventory. Accountability at Tier 2: named owner with quarterly review cadence. Accountability at Tier 3: named owner with formal incident response responsibility, named on the AI Decision Log custom object covered in Article 5.
Proportionality is the principle that lets the other principles scale without breaking the org. Without proportionality, you either drown the team in process for low-risk changes or wave through high-risk deployments because the process is impossible to apply at the volume requested.
What This Looks Like in Practice
The nonprofit with the autocorrect proposal received a revised governance model two months after we engaged. The 12-person committee now reviews Tier 3 only. Tier 2 deployments go through a three-person standing review group (IT director, program lead, named project owner). Tier 1 deployments are approved by the system administrator with documentation in the AI inventory.
The committee meets monthly to review Tier 3 work, sees board-level metrics on AI deployments across all tiers, and reviews any incidents from the prior month. The committee no longer reviews autocorrect.
The Agentforce deployment that originally took 30 minutes was redone with full Tier 3 controls. It took six weeks. It also caught two issues that the original 30-minute review missed: the integration user had a System Administrator profile from a 2022 integration that nobody had cleaned up, and the agent's send-on-behalf authority extended to a list of donors who had explicitly opted out of email contact. Both issues were resolved before launch. The agent is now live, documented, and has a measurable reduction in donor outreach response time.
The committee chair told me the new model freed up 14 hours per month of committee time and gave them confidence in approvals for the first time. Nobody said it was easier. They said it was right.
What's Next
The next article in this series covers Reversibility. The Memorial Day article. The rollback plan that nobody writes until they need it. If your AI deployment has authority to modify records or send communication, the rollback plan question is the one that exposes whether the deployment was actually ready.
If your org is running every AI decision through the same review, or if the review is "we will figure it out as we go," the AI Readiness Scorecard is the right starting point. The Proportionality questions sit in the Governance Readiness section.
Take the AI Readiness Scorecard: clearconciseconsulting.com/scorecard
Schedule a 15-minute call: scheduler.zoom.us/jeremy-carmona
Read the AI Governance service page: clearconciseconsulting.com/services/ai-governance