
The Six Governance Checkpoints: A Real Engagement, Walked Through
This is the eighth article in the May 2026 AI CoE series. The previous seven covered the principles. This one is the application.
A regional healthcare nonprofit engaged CCC last year to deploy an Agentforce-based intake triage agent. The agent's job was to read incoming patient intake forms, classify symptom severity, and route the case to the appropriate clinical team. Tier 3 by every measure: PHI exposure, classification authority, external impact on patient care.
The engagement ran 11 weeks. Three weeks of configuration. Eight weeks of governance. By the time the agent went live, it had passed through every CCC governance checkpoint. Two of them stopped the engagement. One caught a permission issue nobody had seen. One revealed a bias risk that would have shipped silently.
This article walks the engagement through all six checkpoints. Names and details have been changed. The pattern is real.
The Six Checkpoints
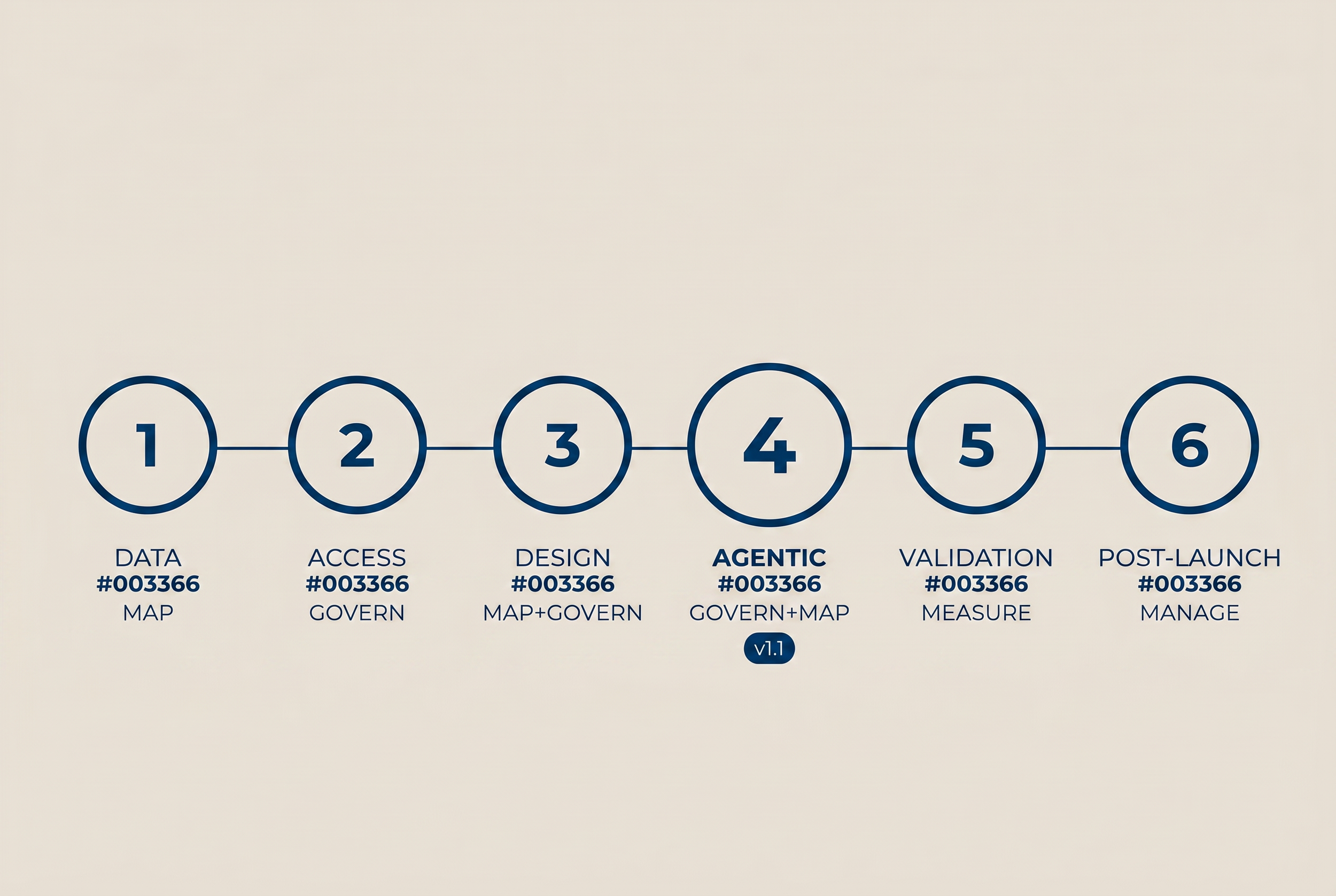
The CCC AI CoE runs every Tier 2 or Tier 3 engagement through six mandatory governance checkpoints. Each is pass/fail. Engagements do not proceed until gate criteria are met. The checkpoints map to the four NIST AI RMF functions: Govern, Map, Measure, Manage.
- Data Readiness (MAP)
- Permission and Access (GOVERN)
- Design Review (MAP plus GOVERN)
- Agentic Governance Review (GOVERN plus MAP)
- Pre-Production Validation (MEASURE)
- Post-Launch Governance (MANAGE)
Checkpoint 1: Data Readiness
Gate criteria: data quality score 7 of 10 or higher across the 10-metric SOQL audit. Sharing model documented. Data ownership confirmed.
What happened in the engagement: the org's initial data quality score was 5.2. The duplicate rate on Contact records was 17%. The completion rate on the symptom_description field, which the agent would read to classify severity, was 71%. Approximately 8,400 active records had no last-updated date in the past three years.
The engagement stopped at Checkpoint 1 for four weeks.
Work performed during the stop:
- Duplicate consolidation across 11,200 Contact records
- Required-field enforcement on the symptom_description field at the form layer
- Inactive-record archival workflow standing up a clean data set for the agent to operate on
- Sharing model documentation showing which clinical teams could see which patient records
When Checkpoint 1 reopened, the score was 7.4. Not perfect. Acceptable. The engagement proceeded.
Lesson worth carrying: the most expensive checkpoint to skip is the first one. Every downstream checkpoint assumes the data is ready. If the data is not ready and you proceed, the rest of the engagement runs on a foundation that will eventually crack.
Checkpoint 2: Permission and Access
Gate criteria: field-level security verified on every object the agent touches. Trust Layer configured. Integration user permission set audited and least-privilege confirmed.
What happened: the integration user the agent would run as had been created in 2022 for an unrelated marketing automation integration. The user had System Administrator profile assigned. The user had not been touched in two years. The user also had a Permission Set assigned that granted Modify All Data on Account, Contact, and seven custom objects.
This was the issue that would have shipped silently. The marketing integration had been decommissioned. The integration user remained. The new agent would have inherited System Administrator authority through the existing user, and nobody would have noticed because the integration user pre-dated the agent project.
The engagement stopped at Checkpoint 2 for one week.
Work performed:
- Created a new dedicated integration user for the agent
- Built a least-privilege Permission Set with read access to Contact and Case, write access to Case only on the four fields the agent would modify
- Confirmed Trust Layer was active and the agent's prompts were configured to mask PHI at the prompt layer per Article 4 of this series
- Documented the permission audit and named the system administrator responsible for quarterly review
The legacy 2022 integration user was deactivated. The Permission Set Modify All Data assignment was removed across all integration users. Standard ongoing hygiene that the engagement created the forcing function to perform.
When Checkpoint 2 reopened, the agent was running on a least-privilege user. The engagement proceeded.
Checkpoint 3: Design Review
Gate criteria: use case risk classified per the Article 6 framework. Human oversight defined per Article 3. Documentation drafted per the Article 4 four-audience standard. Accountability assigned per Article 5.
What happened: this is where the engagement stopped a second time. The original design had no documented human review gate before the agent committed a severity classification to the Case record. The team's logic: "the clinical staff will see the classification on the Case page when they open it." That is not a review gate. That is a notification.
Work performed during the second stop:
- Designed an explicit human review gate: agent writes the classification to a "Proposed_Severity__c" field, not the official Case_Severity__c field. Clinical reviewer confirms or overrides within 30 minutes during business hours.
- Wrote the four-audience documentation per Article 4: executive summary, project plan, admin runbook, end-user job aid.
- Named the medical director as the AI Decision Log owner per Article 5. Quarterly review. Annual board reporting.
- Classified the use case at Tier 3 per Article 6. Six-week governance review confirmed. Multi-stage human review confirmed.
The engagement stopped for two weeks at Checkpoint 3. The team initially pushed back on the human review gate. The argument was efficiency. The pushback was answered by walking through what would happen if the agent classified a high-severity case as routine. The clinical reviewer's 30-minute window was the difference between a triage error and a near miss. Two weeks of design work prevented an outcome that no governance committee would have wanted to discuss six months later.
Checkpoint 4: Agentic Governance Review
Gate criteria: agent action boundaries documented and tested. Session Tracing enabled. Topic restrictions configured. Tool authorization scoped. Behavior governance written into the agent's system prompt.
What happened: this is the checkpoint that most engagements have not had to run before 2026. The introduction of Headless 360 and broader Agentforce action authority made it a required gate.
The agent's original system prompt allowed it to read the patient intake form and write the proposed severity. It did not explicitly restrict the agent from invoking other tools available in the org. With the org's tool permissions as configured, the agent could have invoked an outbound email tool, a SOQL query tool with access to the entire patient roster, and a calendar tool.
None of those tools should have been available to the triage agent. They had not been deliberately granted. They were available because the agent inherited tool authorization from the integration user's Permission Set, which had been configured before the Agentic Governance Review was a standard checkpoint.
Work performed:
- Defined an explicit allowlist of tools the agent could invoke: read intake form, write proposed severity field. Two tools.
- Restricted the agent's topics: triage classification only. Prompt explicitly refuses any request that does not match the topic.
- Enabled Session Tracing so every agent action was logged with the prompt, the tool calls, and the response.
- Wrote a kill switch procedure tied to the new dedicated integration user from Checkpoint 2.
The engagement did not stop at Checkpoint 4 for as long as Checkpoints 1 or 3, but the work performed was the most consequential. The agent's bounded tool authorization is the single configuration choice that makes the deployment safe at scale.
Checkpoint 5: Pre-Production Validation
Gate criteria: bias and fairness testing conducted on a representative sample. Rollback drill executed in a Full sandbox per the Article 7 framework. Pilot testing with at least three clinical reviewers.
What happened: bias testing surfaced the issue that would have shipped silently. The agent was tested on a representative sample of 400 historical intake forms, classified by clinical staff as the ground truth, run through the agent for comparison.
The agent agreed with clinical staff on 87% of cases. Acceptable headline number. The breakdown by patient demographic was where the issue surfaced. The agent's accuracy on patients whose intake forms were submitted in Spanish was 71%, materially lower than the 89% on English-language intake forms. The agent's prompt had been written and tested in English. Spanish-language intake forms were getting classified less reliably.
This is not a unique issue. It is a documented failure mode in clinical AI systems. The bias testing is the checkpoint that catches it before deployment.
Work performed:
- Updated the agent's prompt to explicitly handle Spanish-language inputs and translate before classifying
- Re-ran the bias test on a fresh sample of 200 Spanish-language intakes. Accuracy moved to 86%. Acceptable.
- Documented the language-fluency limitation in the AI Decision Log: the agent is currently validated for English and Spanish only, additional languages require revalidation
- Executed the rollback drill in a Full sandbox per Article 7. The drill took 90 minutes including the post-drill retrospective.
- Conducted pilot testing with three clinical reviewers over two weeks. The reviewers caught two more design issues that surfaced only in live workflow. Both were fixed.
When Checkpoint 5 closed, the agent had documented validated performance, a tested rollback procedure, and pilot-confirmed workflow integration. The engagement proceeded to launch.
Checkpoint 6: Post-Launch Governance
Gate criteria: 30-day review scheduled. Drift indicators baselined. Incident response runbook published. Quarterly review cadence committed.
What happened: this checkpoint is ongoing. The agent went live in week 11. The 30-day review was held on day 31 with the medical director, the system administrator, the project sponsor, and CCC.
The 30-day review found:
- Agent agreement rate with clinical reviewers held at 86% across the first 30 days, consistent with pre-production validation
- Two cases where the clinical reviewer overrode the agent's classification. Both overrides were correct. The cases were reviewed for whether they revealed a new failure mode. Conclusion: the agent's edge-case handling on patients with multiple comorbidities was less reliable. Documented for the next prompt iteration.
- Zero incidents requiring rollback. The kill switch had not been needed.
- Drift baseline established: agreement rate, override rate, response latency, language distribution. Quarterly review will compare against this baseline.
The named medical director will own the AI Decision Log going forward. CCC's engagement closed at the 30-day review. The org continues quarterly self-review per the runbook.
What This Engagement Cost
11 weeks. Eight of them governance work. Three of them configuration.
The configuration could have shipped in three weeks alone. It would have shipped with a System Administrator integration user, no human review gate, no bias testing, no language-fluency validation, no Session Tracing, no rollback drill.
The agent would have been live faster. Whether the deployment would still be live, or whether it would have shipped a bias error or a permission incident, is the question that the engagement answered by running the checkpoints.
The eight governance weeks were not slow. They were the work.
What This Series Was
Eight articles. One per principle. One per the wrap.
The principles, in order:
- Data First
- Human Oversight
- Transparency
- Accountability
- Proportionality
- Reversibility
The structure that holds them: Six Governance Checkpoints. Pass/fail. Documented. Reviewable.
The CCC AI Center of Excellence is published in full at clearconciseconsulting.com/ai-center-of-excellence. The framework is free. The principles are not new ideas. The work of applying them inside a Salesforce org is what the practice does.
If your org is standing up an AI deployment this quarter, the AI Readiness Scorecard is the right starting point. If your score lands below 70, the foundational work is what comes first. If it lands above 70, the engagement focuses on the specific checkpoint where you are weakest.
Either way, the order is the same. Data first. Then permissions. Then human oversight. Then deployment.
This concludes the May 2026 AI CoE series.
Take the AI Readiness Scorecard: clearconciseconsulting.com/scorecard
Schedule a 15-minute call: scheduler.zoom.us/jeremy-carmona
Read the AI CoE charter: clearconciseconsulting.com/ai-center-of-excellence